How to store and share datasets on PortML
Working on machine learning projects comes with the challenge of storing and organizing datasets. This can slow down a workflow. In collaborative projects everyone should have access to the same datasets at any time. PortML offers a solution by providing a secure, private cloud where you can easily store and share datasets, models and experiments in an organized manner. In this blog, we will look at how we can store and access datasets on PortML using the Python API.
Storing a dataset
For the sake of simplicity, we will upload the well known iris dataset. Download the dataset from the UCI website and read it into a pandas dataframe:
import pandas as pd
data = pd.read_csv('iris.data', sep=',')
data.columns = ['sepal_length',
'sepal_width',
'petal_length',
'petal_width',
'class']
print(data.head())
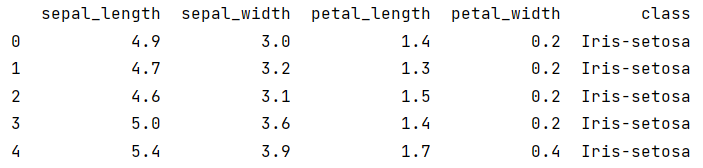
There we go! The iris dataset is a clean dataset, so no further preprocessing is necessary.
1. Connect to PortML
To get the dataset on PortML, we must first install OpenML. Open the command prompt and use pip to easily install openml:
pip install openml
OpenML is an open platform build by machine learning experts for sharing datasets, algorithms and experiments with the goal of improving collaboration and reproducibility in the machine learning community. Being an open source project, OpenML is constantly improving and evolving by contribution from the community. PortML is working together closely with OpenML to offer the rich functionalities and tools of OpenML to corporates and institutions in the form of a managed, secured platform.
We do not want to use the OpenML platform, but we can use the Python API (see docs) to connect to our PortML server. For this you will need your API-key which you can find on your profile. Connect to PortML using:
import openml openml.config.server = "PORTML_SERVER_URL" openml.config.apikey = "YOUR_API_KEY"
2. Create dataset object
We are now able access our secured cloud. We will create an OpenML dataset object that contains the data, as well as all the information about the dataset using the method create_dataset:
iris_dataset = openml.datasets.create_dataset(
name="Iris",
description="This is perhaps the best known database to be found in the pattern recognition literature. \
Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) \
The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. \
One class is linearly separable from the other 2; the latter are NOT linearly separable from each other.",
creator="R.A. Fischer",
contributor=None,
collection_date="1-7-1988",
language="English",
licence=None,
ignore_attribute=None,
citation="UCI Machine Learning Repository",
original_data_url="https://archive.ics.uci.edu/ml/datasets/iris",
version_label="Example",
data=data,
attributes="auto",
default_target_attribute="class",
)
Those are a lot of arguments: check out the documentation of create_dataset for an extensive description. For this tutorial the most important are data, attributes and default_target_attribute. Notice how we can directly input the dataframe and let PortML automatically read the attribute names from the dataframe column names by specifying attributes="auto". Alternatively, you can provide a list with the column names and they will be assigned to the columns of the dataset. We specify the target attribute, which is ‘class’, by default_target_attribute="class" and then we’re done!
3. Upload to PortML
Now we’re just one line away from uploading our dataset:
iris_dataset.publish()
If all is well, we can view our dataset and its information on the PortML webpage after logging in:

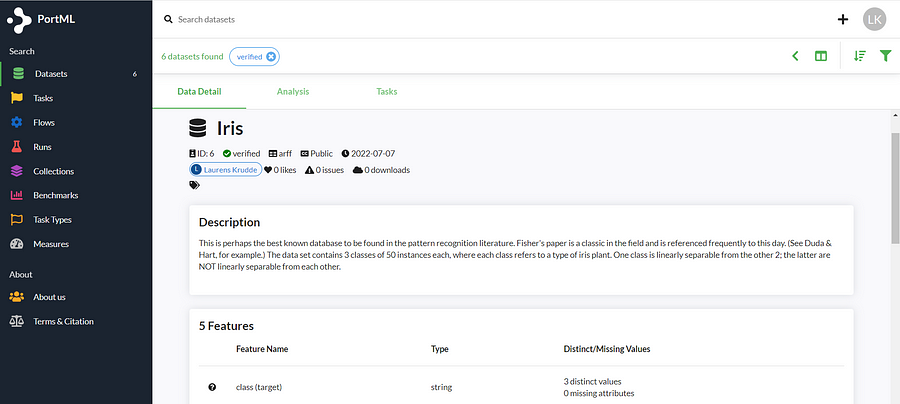
There we go! The iris dataset is stored safely in your secured PortML cloud where you and your team can easily access it at any time.
Retrieving a dataset
Let’s say you or a team member needs to use the dataset. You can retrieve the dataset with its information as an OpenML dataset object using the function get_dataset by its id (see docs):
dataset = openml.datasets.get_dataset(6) print(dataset)
OpenML Dataset ============== Name..........: Iris Version.......: 1 Format........: arff Upload Date...: 2022-07-07 22:13:45 Licence.......: Public Download URL..: http://demo.portml.com/data/v1/download/16/Iris.arff # of features.: 5 # of instances: 150
The dataset itself can be retrieved (as a dataframe) using the method get_data:
dataset_df = dataset.get_data(dataset_format='dataframe')[0] print(dataset_df)
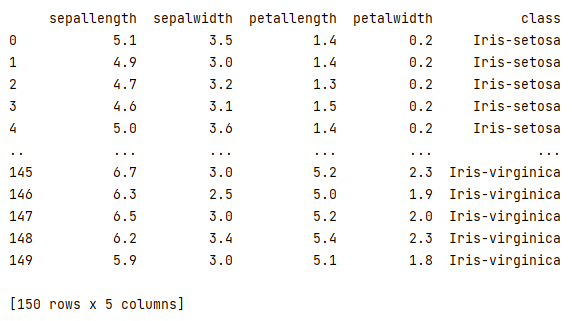
There we go! With two lines of code we retrieved the dataset again. The dataset is now accessible for you and your team at any time. Making collaboration easy!
Try it out on OpenML!
As mentioned in the blog, PortML is bringing the functionalities and tools from OpenML to a managed, secured platform. Curious to get a feel of the platform? Go to openml.org, create an account and test it out!